
Getting past the simplistic hello world getting started consumer
There’s plenty of examples you can search for that demonstrate how to go about consuming simple messages in Mule from a Kafka Consumer.
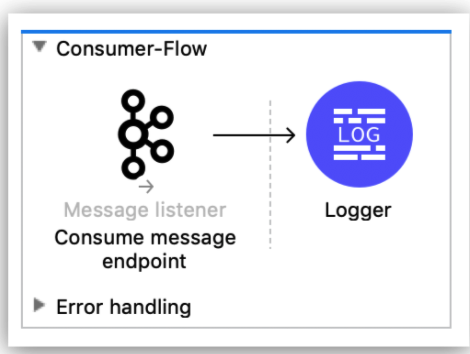
Most of the simple examples you’ll find will look like this one, which is right out of the Mule documentation.
However, in the real world, Kafka message producers prefer sending an array of messages in batches – the producer will attempt to batch records together into fewer requests whenever multiple records are being sent to the same partition. This helps performance on both the client and the server. This pattern establishes the default batch size in bytes. If you attempt to work with an array of messages in the same way as a simple message, you’ll certainly get an error.
Typical example of a simple Kafka consumer flow
<!-- Typical simple example for consuming Kafka messages -->
<flow name="Consumer-Flow" >
<kafka:message-listener doc:name="Consume message endpoint"
config-ref="Apache_Kafka_Consumer_configuration"/>
<logger level="INFO" doc:name="Logger" message="'New message arrived: ' ++ payload ++ &quot;, key:&quot; ++ attributes.key ++ &quot;, partition:&quot; ++ attributes.partition ++ &quot;, offset:&quot; ++ attributes.offset"/>
</flow>With an array of messages, before you can get to the payload elements you’re going to need to unpack the Kafka message object that wraps the byte[ ] stream. Complex messages you receive from the Kafka Consumer will come wrapped in a com.mulesoft.connectors.kafka.api.source.Record object which you’ll need to convert into a java.io.ByteArrayInputStream object before you can work with the payload, as you do with messages you receive from other Mule connectors.
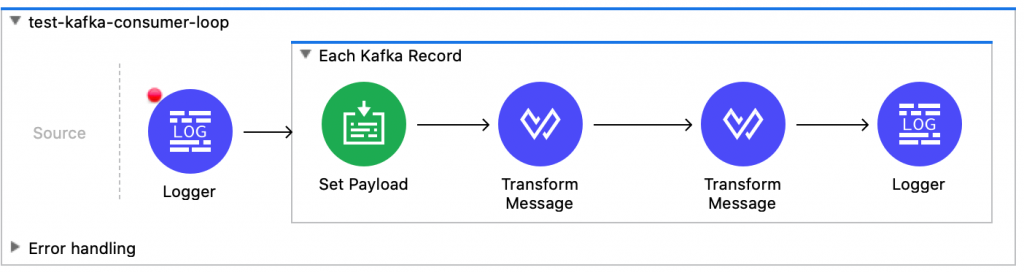
Here’s a sample test flow which I created to demonstrate the steps you’ll need to perform. In the Each Kafka Record loop, you’re going to need to iterate through collection payload.payload to get to each java.io.ByteArrayInputStream object. In the Set Payload task, I assign the media type as application/json to provide a hint of the data type we’re processing to help the DW with transforms. The payload element is set to itself, passing through unchanged.
Those twos steps are where the magic happens. Once we have a streaming byte array for our payload, it’s business as usual. In the first transform we convert the byte array into a JSON object. The second transform is just for fun, to create a HashMap variable from the JSON.
The first DW Transform creates our JSON object
%dw 2.0
output application/json
//input payload application/json
---
payloadIn the next DW Transform I pass the JSON object through the transform as shown in the code snippet above and create a Variable to contain a HashMap of the JSON. This is a trivial step once our message is a JSON object.
Prior to Mule version 4 if you wanted to convert a byte stream into an object map you might have to wrangle the payload with some Groovy code. This is no longer needed in version 4, byte arrays can be simply transformed by DataWeave into Java HashMaps. Muleoft advises against twiddling with byte array streams.
A solution for doing this is shown for below, in case you still have earlier versions of Mule that may need to handle byte array conversion to JSON.
# Groovy snippet converts JSON byte stream into a HashMap
import groovy.json.*
import java.nio.charset.StandardCharsets
int len = payload.available()
byte[] bytes = new byte[len]
payload.read(bytes, 0, len)
String jsonStr = new String(bytes, StandardCharsets.UTF_8)
def slurper = new JsonSlurper()
payload = slurper.parseText(jsonStr)If you get errors from AnyPoint Studio that Nashorn is the only scripting engin available, you may need to follow guidance in the Mulesoft Post-Upgrade steps to configure sharedLibraries and dependency tags in pom.xml.
Groovy engine dependency configuration
<!-- Ensure the Groovy Scripting engine is defined for both -->
<sharedLibrary>
<groupId>org.codehaus.groovy</groupId>
<artifactId>groovy-all</artifactId>
</sharedLibrary>
...
<dependency>
<groupId>org.codehaus.groovy</groupId>
<artifactId>groovy-all</artifactId>
<version>2.4.16</version>
<classifier>indy</classifier>
</dependency>It took me some time to understand how to process complex messages from the Kafka Consumer as there were no good examples I could find at the time of this post, so I thought I would create this one to share with the community.
I hope this article helps you understand better how to go about processing complex messages from Kafka consumer.
Mitch Dresdner
Mitch enjoys tinkering with tech across a wide range of disciplines. He loves learning new things and sharing his interests. His work interests run the gamut of: application integration, scalable secure clusters, embedded systems, and user interfaces. After hours you might find him dabbling in the hobby space with Raspberry Pi's, drones, photography, home wine making and other ferments.